ISTEX et plein texte structuré
À l’heure de rédaction de ce billet de blog, la plateforme ISTEX met à disposition plus de 18 millions de documents scientifiques au format PDF à l’ensemble de la communauté de l’Enseignement Supérieur et de la Recherche. Au delà d’un accès performant et pérenne aux documents PDF, la disponibilité de documents pleins textes structurés en XML simplifie également considérablement l’application d’outils de TDM (Text and Data Mining) pour les chercheurs en analyse de données scientifiques.
Lorsqu’un éditeur scientifique fournit des documents pleins textes XML, il est possible de transformer le format XML propre à l’éditeur sans perte d’information dans un format TEI unique grâce à un outil comme Pub2TEI. Pub2TEI est un projet Open Source rassemblant un jeu de feuilles de style couvrant les formats XML des principaux éditeurs présents dans ISTEX.
Cependant, la grande majorité des ressources ISTEX (plus de 90%) n’est disponible qu’au format PDF, les éditeurs ne disposant eux-mêmes pas des documents pleins textes complémentaires. Comment, pour ces 90%, mettre à disposition un format uniforme adapté au TDM ?
Grobid
Grobid (GeneRation Of Bibliographic Data) est un outil utilisé dans le projet ISTEX pour repérer et structurer les références bibliographiques dans les articles scientifiques en format PDF. Cet outil génère actuellement les fichiers TEI refBibs visibles sur le démonstrateur d’ISTEX.
Grobid permet également de convertir un PDF brut d’article scientifique en un document TEI structuré reprenant l’ensemble du plein texte, incluant l’identification des titres de sections, paragraphes, des figures, tables, équations, etc. Cette fonctionnalité – plus ambitieuse et complexe que la simple extraction des références bibliographiques – permettrait de mettre à disposition des versions pleins textes structurés pour l’ensemble des ressources ISTEX dans un format TEI unique et homogène.
Pour avoir plus d’informations sur cet outil développé en Open Source sous licence Apache 2, vous pouvez consulter ce lien : http://grobid.readthedocs.io/en/latest/Introduction.
Il n’existe à notre connaissance actuellement que deux autres outils permettant une telle conversion: pdfx et CERMINE. Sans considération de précisions des extractions et temps de traitement, pdfx n’est pas disponible en open source et CERMINE ne couvre qu’un jeu de structures limité du corps de texte.
Grobid convertit un PDF par des techniques d’apprentissage automatique (CRF). La version publique de Grobid a été entraînée à l’aide de documents de PubMed Central (PMC) et HAL qui peuvent faire l’objet de traitement TDM et dérivation sans contrainte. Afin d’améliorer les performances de l’outil sur les articles du corpus ISTEX, des données d’entraînement spécifiques sont à ajouter. Une particularité de Grobid est d’utiliser en cascade différents modèles : chaque modèle se spécialise dans une sous-tâche de structuration, ce qui permet de diviser les données d’apprentissage.
Deux modèles sont tout particulièrement utiles pour la structuration d’un plein texte : le modèle segmentation et le modèle fulltext. Ce premier billet de blog se consacre à nos travaux sur le modèle segmentation, le modèle fulltext faisant l’objet d’un second billet : /entrainement-du-…d-par-lequipe-rd/ .
Modèle segmentation de Grobid
Ce modèle a pour but d’identifier les grands segments logiques d’un article scientifique, comme la page de garde, l’entête, le corps de texte, la section bibliographique, les annexes, etc.
Le modèle segmentation de Grobid correspond aux balises TEI suivantes :
- <front> : éléments relatifs au header du document (titre, résumé, auteurs, éditeur…)
- <note place= »footnote »> : pied de page et notes de bas de page
- <note place= »headnote »> : en-tête de page
- <body> : corps du texte (comprenant les tableaux et figures)
- <listBibl> : références bibliographiques
- <page> : numéro de page
- <div type= »annex »> : annexes, comprenant des commentaires et informations supplémentaires de l’article
- <div type= »acknowledgement »> : remerciements
- <titlePage> : page de garde d’un article
Consolidation de l’entraînement du modèle segmentation avec des documents ISTEX
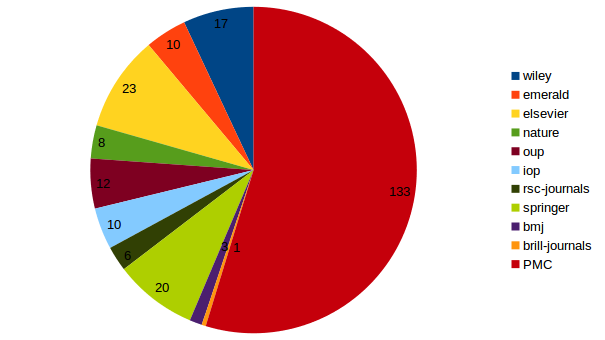
Le modèle segmentation de Grobid disponible dans la distribution publique sous GitHub a été entraîné sur 133 documents de PubMed Central (PMC) et HAL. L’équipe ISTEX R&D a ajouté 91 documents ISTEX à ce corpus d’entraînement. Le nouveau modèle est donc entraîné sur 224 documents au total.
Afin d’être exploitable pour l’entraînement automatique, un document du corpus d’entraînement doit être annoté de façon à identifier explicitement chaque segment attendu. Ceci est réalisé de façon semi-automatique, incluant une validation manuelle pouvant être relativement longue.
Voici la répartition par corpus des documents utilisés pour l’entraînement du modèle segmentation par l’équipe R&D :
Évaluation du modèle segmentation
L’évaluation est la pierre angulaire de l’apprentissage automatique. Il est essentiel de mesurer la performance d’un modèle au fur et à mesure de sa conception afin de diriger et optimiser le travail d’ingénierie. Dans le cas présent, nous avons mesuré deux aspects complémentaires :
- l’impact de l’ajout de documents annotés ISTEX dans le corpus d’apprentissage pour segmenter des documents PDF ISTEX : dans quelle mesure améliore-t’on le modèle avec cet ajout? Le coûteux travail d’annotation de ces documents est-il justifié par un gain de performance?
- la précision générale du modèle sur l’ensemble des documents ISTEX et non-ISTEX : quelle niveau de précision peut-on attendre sur des documents tout venant ? Est-ce que ce niveau de qualité est acceptable pour un passage en production ?
Sous-corpus ISTEX d’évaluation du modèle segmentation
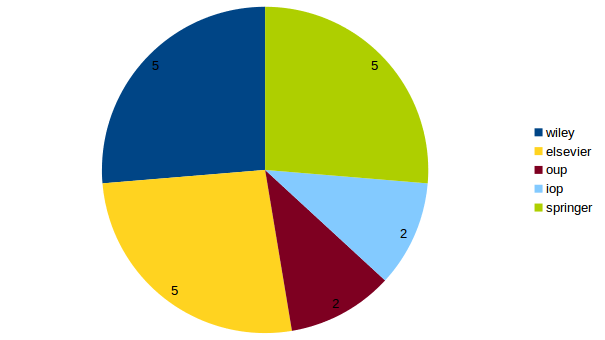
Nous avons utilisé 19 documents ISTEX pour créer un corpus d’évaluation propre à ISTEX ISTEX permettant de mesurer l’évolution du modèle segmentation. Voici la répartition par éditeur des documents utilisés pour ce sous-corpus d’évaluation :
Évaluation sur le sous-corpus ISTEX de l’impact de l’ajout des documents ISTEX au corpus d’entraînement
- Dans cette partie, nous voulons voir si, lorsque nous ajoutons des documents ISTEX au premier corpus d’entraînement PMC/HAL (133 documents), nous obtenons une amélioration du modèle pour le traitement de documents ISTEX. Voici les étapes de cette évaluation:
- Évaluation du modèle construit avec les 133 documents PMC sur le sous-corpus d’évaluation ISTEX.
- Entraînement du modèle segmentation avec les 91 documents ISTEX + 133 documents PMC/HAL.
- Évaluation du modèle construit avec 91 documents ISTEX + 133 documents PMC/HAL sur le sous-corpus d’évaluation ISTEX.
- Comparaison des F-score (pour chaque type de segment) de ces deux modèles.
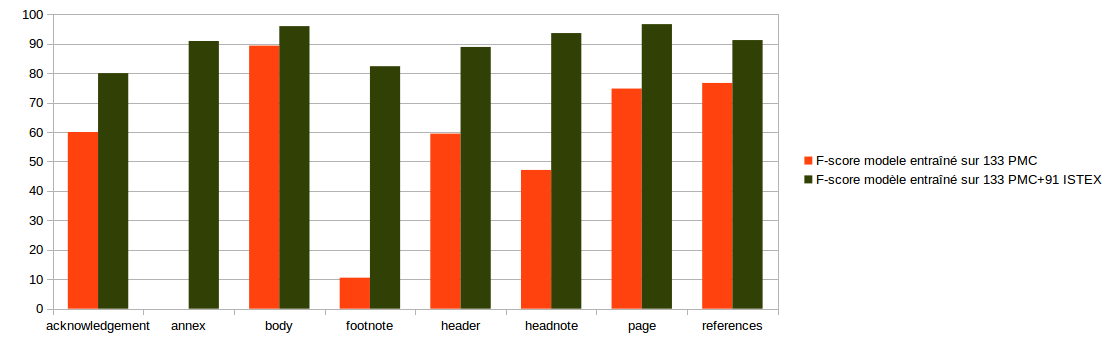
Il faut noter que les scores présentés ici sont établis au niveau d’un champ complet. Autrement dit un segment est considéré comme incorrect dès qu’un de ses tokens est mal étiqueté. En pratique, des champs de grande taille peuvent tout de même donner lieu à des structurations de qualité acceptable même si quelques uns de leurs tokens sont incorrectement classifiés.
Ce diagramme montre une nette amélioration des résultats de F-score pour toutes les balises en général après ajout des documents ISTEX dans le corpus d’entraînement. Cette amélioration est particulièrement marquée pour des parties très variables d’un journal à l’autre : les numéros de page, header, footnote et acknowledgment.
Évaluation générale de la performance du modèle segmentation
Afin d’évaluer la précision du nouveau modèle sur des documents tout venant (ISTEX et non-ISTEX), nous utilisons l’approche classique de partitionnement aléatoire multiple du corpus annoté en corpus d’entraînement (80%) et corpus d’évaluation (20%). La moyenne des scores obtenus pour chaque partitionnement est utilisée pour obtenir des scores définitifs les moins biaisés possibles (plus exactement les scores sont aussi biaisés que le corpus, mais sans les effets des partitionnements).
L’ensemble des documents annotés représente 243 documents (19 documents du corpus d’évaluation sont ajoutés). Voici les F-score obtenus pour chaque balise après cette évaluation :
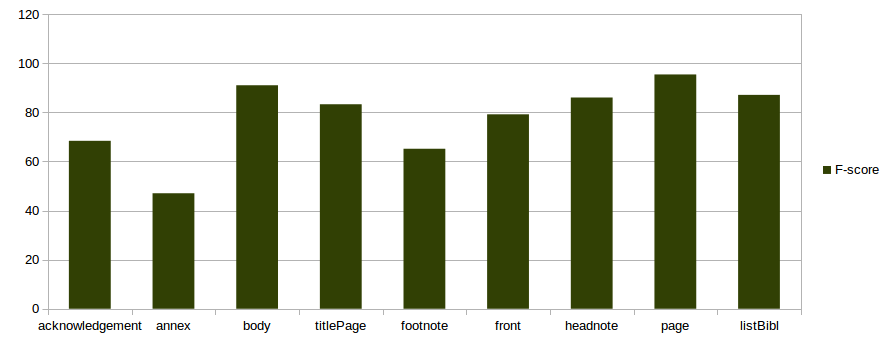
Nous pouvons considérer que la section bibliographique, l’entête, les numéros de page et le corps de texte sont fiables. Les segments moins présents dans le corpus d’apprentissage comme les annexes, qui n’ont ni un format stable ni un endroit fixe dans les documents, sont plus difficiles à identifier.
Nous vous invitons à lire la suite de cet article sur la page suivante :/entrainement-du-…id-par-equipe-rd/

Besoin d'aide ?
Consultez notre Faq, la documentation Istex ou nos tutoriels
N’hésitez pas à nous contacter si besoin, nous reviendrons rapidement vers vous !
Écrivez-nous
