Le présent billet a pour but d’apporter quelques précisions sur le format de retour de l’API, sujet qui vous pose régulièrement question.
La situation actuelle
Actuellement, l’API renvoie les résultats au format JSON sous la forme d’une liste de documents. Chacun d’entre eux est accompagné par un ensemble de métadonnées :
- identifiants (ISSN, DOI…)
- langue du texte
- liste de mots-clés
- résumé
- etc
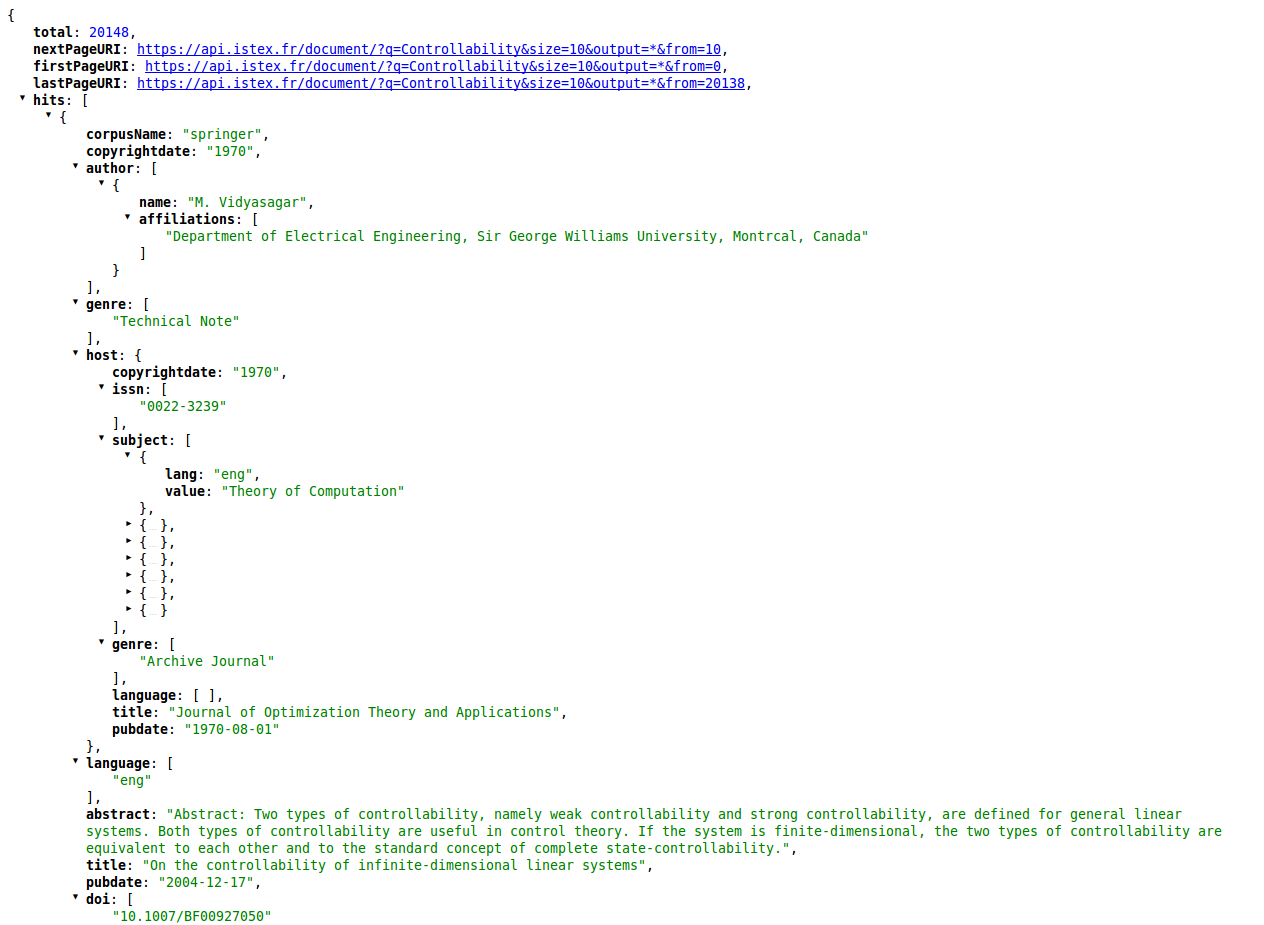
Ces métadonnées ne sont absolument pas complètes. Pour récupérer la totalité d’entre elles, il est nécessaire de consulter la version Mods ou TEI de chaque document trouvé.
Le pourquoi du comment
L’explication est directement liée à la manière dont nous utilisons Elasticsearch, notre moteur de recherche.
Pour rendre l’ensemble des documents cherchables, il est nécessaire de les indexer dans le moteur de recherche en spécifiant un mapping. Ce mapping décrit le plus finement possible quels sont les champs indexés et de quel type ils sont.
L’indexation proprement dite ne se fait pas à partir du fichier d’origine (XML, PDF…) mais dans un format JSON correspondant au mapping précédemment défini.
On passe donc par une étape de conversion Mods vers JSON avant indexation. Celle-ci ne reprend pas l’ensemble des métadonnées contenues dans le fichier Mods, mais seulement une liste prédéfinie.
Et pour l’interrogation ?
Il est important de noter que la structuration même des index impacte fortement la manière de rechercher via l’API.
En effet, lors d’une requête
https://api.istex.fr/document/?q=<requete>
la syntaxe à utiliser pour le paramètre <requete> nécessite de connaître précisément le mapping.
Par exemple, pour trouver des articles dans une revue dont l’ISSN est 0022-3239, il faut utiliser la syntaxe
<requete>=host.issn:"0022-3239"
Une idée d’évolution
Pour permettre la recherche de toutes les métadonnées disponibles et par conséquent leur accès direct via l’API, nous proposons de changer prochainement le mapping / la structuration des index.
L’idée serait de convertir automatiquement l’ensemble des métadonnées (soit MODS, soit TEI) en JSON en suivant une spécification de formatage standard telle que JSONML ou Google Data.
Voilà par exemple à quoi ressemblerait un notice Mods transformée en Json selon la spécification Google Data :
{ mods:
{ xmlns: 'http://www.loc.gov/mods/v3',
'xmlns$xsi': 'http://www.w3.org/2001/XMLSchema-instance',
'xsi$schemaLocation': 'http://www.loc.gov/mods/v3 file://D:/istex/home/etc/xsd/mods.xsd',
version: '3.4',
titleInfo:
{ lang: 'eng',
title: { '$t': 'The manual of cultivated orchid species' },
subTitle: { '$t': 'Revised Edition. By Helmut Bechtel, Phillip Cribb, and Edmund Launert. The MIT Press, 28 Carleton St., Cambridge, MA 02142. ISBN 0-262-02253-2. 1986. 444 pp. $75 (cloth)' } },
name:
{ type: 'personal',
namePart:
[ { type: 'given', '$t': 'James L.' },
{ type: 'family', '$t': 'Luteyn' } ],
affiliation: { '$t': 'New York Botanical Garden, New York, USA' },
role: { roleTerm: { type: 'text', '$t': 'author' } } },
typeOfResource: { '$t': 'text' },
genre: { '$t': 'Book Review' },
originInfo:
{ place: { placeTerm: { type: 'text', '$t': 'New York' } },
publisher: { '$t': 'Springer-Verlag' },
dateValid: { encoding: 'w3cdtf', '$t': '2008-05-30' },
copyrightDate: { encoding: 'w3cdtf', '$t': '1987' } },
language: { languageTerm: { type: 'code', authority: 'iso639-2b', '$t': 'eng' } },
physicalDescription: { internetMediaType: { '$t': 'text/html' } },
relatedItem:
{ type: 'series',
titleInfo:
[ { title: { '$t': 'Brittonia' } },
{ type: 'abbreviated', title: { '$t': 'Brittonia' } } ],
genre: { '$t': 'Archive Journal' },
originInfo:
{ dateIssued: { encoding: 'w3cdtf', '$t': '1987-04-01' },
copyrightDate: { encoding: 'w3cdtf', '$t': '1987' } },
subject:
{ usage: 'primary',
genre: { '$t': 'Life Sciences' },
topic:
[ { '$t': 'Plant Sciences' },
{ '$t': 'Plant Systematics/Taxonomy/Biogeography' },
{ '$t': 'Plant Anatomy/Development' },
{ '$t': 'Plant Physiology' },
{ '$t': 'Plant Ecology' } ] },
identifier:
[ { type: 'ISSN', '$t': '0007-196X' },
{ type: 'ISSN', '$t': 'Electronic: 1938-436X' },
{ type: 'matrixNumber', '$t': '12228' },
{ type: 'local', '$t': 'IssueArticleCount: 43' },
{ type: 'istex',
'$t': '9EEEF43776FB6AEF3F0CA2FACC5A25F5F0FA62E2' } ]
[...]
Une telle modification impacterait donc fortement l’interrogation, car cela impliquerait une bonne connaissance de deux formats :
- le format Mods ou TEI
- la représentation Json « JsonML » ou « Google Data »
Par exemple, une recherche sur les mots du titre s’écrirait :
https://api.istex.fr/document/?q=mods.titleInfo.title.$t:"Controllability"
À vous la parole
Si vous avez des remarques ou des idées, ou encore si vous avez une préférence concernant l’un des formats énoncés, n’hésitez pas à nous en faire part dans les commentaires.

Besoin d'aide ?
Consultez notre Faq, la documentation Istex ou nos tutoriels
N’hésitez pas à nous contacter si besoin, nous reviendrons rapidement vers vous !
Écrivez-nous
