 Dans le cadre du projet ISTEX, l’usage de l’OCR est essentiellement destiné à l’amélioration de plein texte ayant déjà fait l’objet d’une OCRisation par des éditeurs. Dès lors se pose la question d’évaluer la qualité intrinsèque d’un résultat d’OCR afin de déterminer quels documents doivent faire l’objet d’une ré-OCRisation, de sélectionner le meilleur résultat entre différents OCR et mesurer les progrès éventuel d’un travail de paramétrage et de pré/post-traitements autour des outils d’OCR. Voir billet de blog du 09/05/2016: evaluer-les-resultats-docr-dans-le-projet-istex
Dans le cadre du projet ISTEX, l’usage de l’OCR est essentiellement destiné à l’amélioration de plein texte ayant déjà fait l’objet d’une OCRisation par des éditeurs. Dès lors se pose la question d’évaluer la qualité intrinsèque d’un résultat d’OCR afin de déterminer quels documents doivent faire l’objet d’une ré-OCRisation, de sélectionner le meilleur résultat entre différents OCR et mesurer les progrès éventuel d’un travail de paramétrage et de pré/post-traitements autour des outils d’OCR. Voir billet de blog du 09/05/2016: evaluer-les-resultats-docr-dans-le-projet-istex
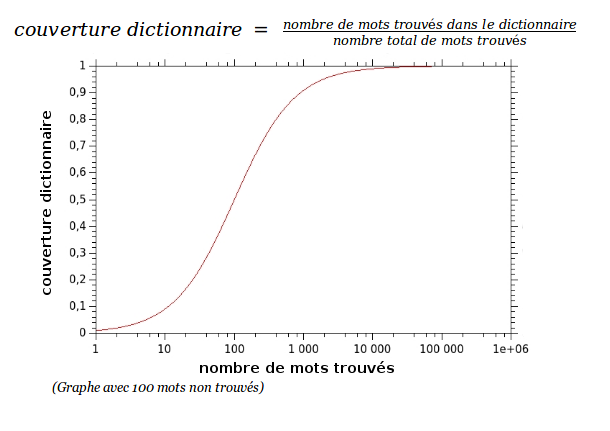
Comme annoncée, la méthode par dictionnaire a été implémentée pour la création de l’indicateur de qualité d’un résultat d’OCR. Les dictionnaires utilisés sont ceux du projet LibreOffice, herbergés sur la plateforme Github (https://github.com/LibreOffice/dictionaries). En résumé, elle consiste à analyser la sortie texte de l’OCR, d’y extraire tous les mots trouvés et de calculer le ratio entre le nombre de mots présents dans le dictionnaire par rapport au nombre total de mots trouvés dans la sortie OCR. Nous avons donc un indicateur OCR calculé de la façon suivante :
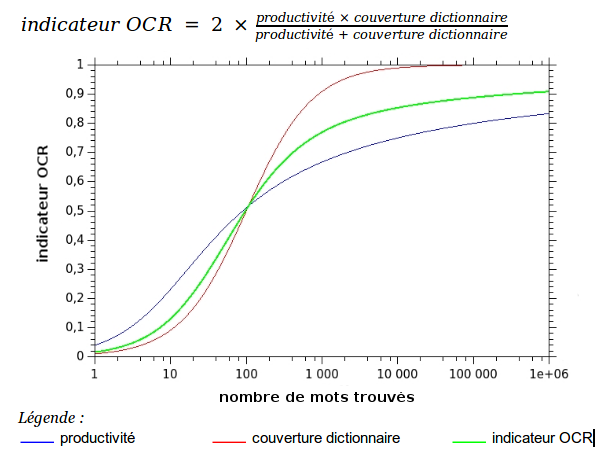
 Par la suite, nous avons ressenti le besoin de pondérer notre indicateur avec le total de mots produits par l’OCR afin d’avoir un indicateur OCR qui prenne en compte la productivité de l’OCRisation. Et après étude, il a été retenu de calculer l’indicateur d’OCR de la façon suivante :
Par la suite, nous avons ressenti le besoin de pondérer notre indicateur avec le total de mots produits par l’OCR afin d’avoir un indicateur OCR qui prenne en compte la productivité de l’OCRisation. Et après étude, il a été retenu de calculer l’indicateur d’OCR de la façon suivante :


Besoin d'aide ?
Consultez notre Faq, la documentation Istex ou nos tutoriels
N’hésitez pas à nous contacter si besoin, nous reviendrons rapidement vers vous !
Écrivez-nous
